zookeeper 之 eznode && watcher
背景
公司里面服务发现的组件用的是zookeeper,一般的过程大概是提供服务的进程会在一个约定的znode下面创建ephemeral znode (以下简称eznode),然后内容中加入该服务的ip和port。别的服务就可以随机在这个约定的znode下挑选一个eznode,解析得到它的ip,port,向其发送tcp请求。
特别地,每个服务进程除了在启动的时候会创建(create)一次这个znode以外,还会定时地尝试创建。这主要是为了防止服务进程的网络和zk服务的网络分区,导致zk服务在一定的时间内(session expiration timeout)没有接收到这个服务进程的心跳从而将其定义为过期。过期会导致eznode被删除,也会导致该服务进程(client)的所有watcher被删除。
接下来,我们就结合Go语言中的github.com/samuel/go-zookeeper/zk库详细的分析一下会话超时和watcher相关的一些知识,并且基于这些知识讨论一下在实际应用中如何通过zk来完成一些分布式相关的任务。
Session State Diagram
官网上边有对session状态迁移的示意图:
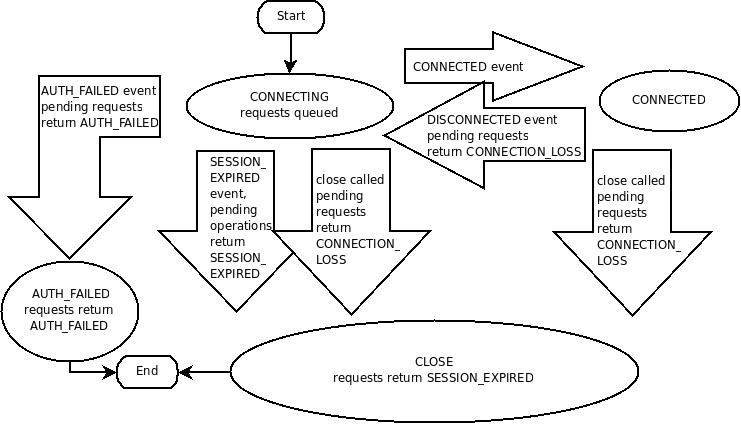
上图中有很多event。Go的zk库中,创建一个连接的之后,会返回一个event的channel(default watcher),这个channel在这个conn被client主动Close之前是总是有效的,它用于接收上图中的各种event。
Session Expiration
定义
When a client (session) becomes partitioned from the ZK serving cluster it will begin searching the list of servers that were specified during session creation. Eventually, when connectivity between the client and at least one of the servers is re-established, the session will either again transition to the “connected” state (if reconnected within the session timeout value) or it will transition to the “expired” state (if reconnected after the session timeout).
需要注意的是:
- 会话超时会导致eznode和watcher都被删除
- 会话超时的判定是由zk server端判定的
- 如果zk集群宕机,一段时间后重启:zk server不会认为client的session超时
-
会话超时的行为当且仅当client和server网络分区的时候才会发生
- 如果client异常退出,那么会话就不存在
- 如果单个server异常退出,那么client会尝试连接新的server,会话继续保持
- 如果server集群异常退出,那么client依然尝试重连,并且直到server重启这段时间不会算在超时时间的记录中
当发生会话超时之后,client不会立即收到expiration event,而是在网络分区问题解决以后重新连接到zk集群之后才会收到这个event。这时候,client需要重新配置会话,包括:创建eznode,设置watcher等。
超时时间
在client创建zk连接的时候,需要传入超时时间,单位为毫秒。注意,zk并不是直接使用指定的值作为超时时间,而是会通过一定的规则在客户端与服务端进行协议,最终确定一个最终的超时时间。
连接zk服务之后,client会每隔一段时间向server发起一个Ping,为了:
- 告知server,client是存活的
- client探测server是否能连通
这个Ping的时间间隔是由zk内部定义的(感觉是与超时时间值成正比),如果client与server网络分区,那么client会立即尝试去连接其他zk server,并且向default watcher发送disconnect event.
每种情况对会话资源影响
接下来讨论下每种情况对会话资源的影响(这里的会话资源指client创建的eznode和watcher)
-
client重启
由于每个会话都是独立的(client和server之间会维护一个id),client重启后创建的会话和之前的会话属于不同的会话。因此,旧的会话的资源全都会被删除。
-
server重启
- 单个server重启,client会收到
disconnect event,然后尝试重连另外的server - server集群重启,client会收到
disconnect event。当server重启后,client的会话不会被认定为超时
- 单个server重启,client会收到
-
网络分区
client会收到
disconnect event。- 当分区问题在超时之前恢复,那么client会收到
connected event,会话资源被保留 - 当分区问题在超时之后恢复,那么client会收到
connected event,expiration event。会话资源需要重新配置
- 当分区问题在超时之前恢复,那么client会收到
实验
见这里
分布式的应用
抢占znode实现高可用
假设有多个节点负责同一个功能,其中一个节点作为主节点对外服务,而其余节点作为备用节点。当主节点宕机或者网络分区,选择一个备用节点作为新的主节点,而旧的主节点停止之前的任务,并且在恢复之后自动降级为备用节点。
我写了一个通用的框架: zkha
Comments