postgresql学习笔记 (v9.6)
- 1 备份与恢复
- 2 基于Log-shipping的高可用
- 3. 服务器设置
- 98. 零散的知识
- 99. 中间件
- 100. 参考资料
1 备份与恢复
PG支持三种类型的备份方式:
-
SQL dump
-
描述:SQL备份。使用
pg_dump备份某个database(不包括cluster-level的对象,例如: role, tablespace),或者使用pg_dumpall备份整个cluster。 -
优点
- 可以在线备份
- 占用空间小
-
缺点
- 使用
pg_dumpall备份整个cluster的时候,由于内部对每个database分别使用pg_dump,虽然保证了每个database内部状态是一致的,但是无法做到database之间(也即整个cluster)的状态是同步的。 - 速度慢
- 使用
-
-
文件系统级别的备份
-
描述:物理备份。使用支持consistent snapshot的文件系统作为
PGDATA目录的挂载介质,在需要备份的时候对该文件系统做一个forzen snapshot。之后在需要恢复备份的时候,将这个snapshot恢复,然后启动服务。由于snapshot保存了所有文件当时的状态,PG会认为刚经历过一次crash,因此会利用WAL进行恢复(这是正常行为)。 -
优点
- 可以在线备份
- 速度快
-
缺点
- 占用空间大
-
-
continuous archiving
-
描述:
basebackup + WAL archive需要先创建一个basebackup(并非一致性的备份),然后利用归档的WAL进行replay,最终恢复一个一致的cluster。这里需要备份的是WAL archive. -
优点
- 不需要创建一个一致性的备份用于恢复,因为那些不一致的地方可以通过后续的WAL追加可以达到一致
- 可以通过持续备份WAL来做到持续备份整个数据库
- 支持PIT(point-in-time)恢复,允许恢复到某个WAL对应的状态
- 允许将WAL复制到另一台机器上,从而创建一个从库
-
缺点
- 无法备份配置文件(因为它们不是通过SQL去修改的,而是手动修改的)
- 需要对每一次WAL archive的失败进行快速的修复,否则如果服务器一旦毁坏,那么从失败点开始的数据都无法恢复
-
以下重点介绍第三种备份的配置。
1.1 基于continuous archiving的备份
由于WAL默认每16MB(编译时确定)保存一份,以数字命名文件名,代表其在WAL sequence上的抽象位置点。如果不设置archive_mode,那么PG仅仅会保留一部分感兴趣的WAL文件,那些位置点早于checkpoint的WAL文件则会被回收(需要文献确认…)。而如果打开了archive_mode,那么每一份新产生的WAL文件都会被输入到archive_command中,由该命令来备份WAL。
1.1.1 配置WAL archiving
需要在postgresql.conf中做以下设置:
wal_level为至少replicaarchive_mode为至少onarchive_command(返回0代表成功归档一个WAL日志,可以运行时修改,需要reload配置。当PG接收到0的返回值以后,它会认为该WAL文件已被正确的备份;否则它会重试)
1.1.2 创建base backup
有两种方式可以创建base backup:
- 使用
pg_basebackup工具 - 使用non-exclusive lowlevel API
1.1.2.1 pg_basebackup创建base backup
1.1.2.2 non-exclusive lowlevel API创建base backup
-
在目标机上使用superuser或者别的有EXECUTE权限的用户连接到源库执行:
SELECT pg_start_backup('label', false, false),这个连接必须一直保持直到备份结束(会执行一次checkpoint)。pg_start_backup(): 第一个参数可以取一个唯一的名字代表这次备份的标识;第二个参数代表是否限定备份使用的I/O量以减少其对其他Query操作的影响(见checkpoint_completion_target);第三个参数代表是否是exclusive,目前exclusive已经被弃用,所以总是false。 -
使用命令备份文件目录(cp, tar, rsync, etc.). 注意:以下源库上的文件不应该备份:
- pg_replslot/*
- pg_xlog/*
- postmaster.pid
- postmaster.opts
-
在与之前start相同的连接中执行:
SELECT * FROM pg_stop_backup(false),这会退出备份模式,在primary上,它还会自动切换下一个WAL segment;如果是在standby上做备份,需要在primary上手动执行pg_switch_xlog,从而保证恢复需要的WAL log都被archive了。这个操作是为了保证备份过程中的最后一个WAL log被archive.pg_stop_backup():的第一个返回值是恢复备份需要的最后一个WAL 位置(也即备份过程中生成的最后一个WAL)的文件名;第二个返回值需要写到一个名为backup_label的文件,位于目标库的PGDATA目录;第三个返回值如果非空的话要写入目标库的PGDATA目录下的名为tablespace_map的文件中。 -
至此,一个完整的备份已经完成。
pg_stop_backup的第一个返回值即是恢复备份需要的最后一个WAL segment的名字。
1.1.2.3 注意事项
-
从PG9.2开始,支持在hot standby上面创建basebackup,但是这个过程和在primary上创建有以下几个区别:
- 不会产生backup history文件(i.e. xxx.backup)
- 不会在开始和结束的时候switch xlog (这也是合理的,否则priamry和standby的xlog不同步了)
更多讨论可以参见:这个mail
1.2 Point-in-time 恢复
基本步骤如下:
- (如果数据库正在运行)停止数据库
- (如果有足够的空间)将数据目录和表空间另存一份
- 删除数据目录和表空间
- 从base backup恢复数据目录和表空间(注意权限和所有权)。如果使用了表空间,则确保pg_tblspc/中的软链接被正确的恢复了
- 删除pg_xlog/目录中的内容(因为这里的WAL文件是在创建basebackup时刻的内容,备份开始以后的WAL都通过
archive_command被归档了) -
If you have unarchived WAL segment files that you saved in step 2, copy them into pg_xlog/. (It is best to copy them, not move them, so you still have the unmodified files if a problem occurs and you have to start over.)
-
在数据目录下创建一个recovery.conf文件,并且填写相关内容(例如:
restore_command,stopping_point)。同时,修改pg_hba.conf以阻止用户连接这个数据库。特别地,如果你在recovery.conf中通过
recovery_target_time或者recovery_target_name指定恢复点并且做了多次恢复,那么你应该总是指定相应的recovery_target_timeline!!!对于
recovery_target_name,可以在创建的时候将创建的时候的当时的timeline记录下来.对于
recovery_target_timeline,可以参考2.13.5节的方法。 - 启动服务器。此时,服务器会进入恢复模式,并且会通过
restore_command读取archived的WAL log并且应用它们。如果中途出现任何错误,可以重启服务,重启后它会继续恢复。直到全部的WAL日志被应用完毕,它会将recovery.conf重命名为recovery.done,并且开始正常的数据库操作。 - 检查数据库是否已经恢复,如果是,则修改pg_hba.conf恢复用户的访问权
如果仅仅需要的是从备份恢复(而非PIT恢复),那么执行到第四步即可。
1.3 timeline
假设你在周四晚上5:15PM误删了一个库,但是当时并没有意识到,直到周日早上才发现。此时,你可能会拿出备份恢复到周四晚上5:14PM的状态。之后,你意识到实际上那个被误删的库其实并不重要,而从周四到周日的数据的丢失更严重。此时,如果你想再恢复到周日早上的状态,这是做不到的。这是因为数据库会将原本周四5:15PM以后的WAL日志修改成你之前恢复的那个点以后发生的事件。
幸运的是,PG通过timeline的概念解决了这个问题。在PG中,每当一个恢复操作成功就会新产生一个timeline,这个timeline以ID的形式作为WAL日志文件名的一部分,仅记录该次恢复之后产生的WAL日志。同时,PG会创建timeline history文件,用于记录这个恢复是属于哪个timeline以及恢复到何时的。
示意图:
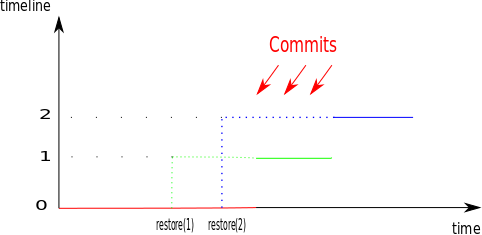
1.4 实践
2 基于Log-shipping的高可用
这章的内容基于PG9.6官网
除了基于log-shipping的高可用方案外,还有一些别的方案,可以参加官网的这个页面。
对于基于Log-shipping的高可用方案,还有如下几个维度可以细分:
-
复制方式:
PG支持日志归档(file based)和流式复制(record based or streaming)。
- 日志归档: 每次会传输一个WAL log segment(16MB, 编译期决定), 在recovery.conf的
restore_command中定义如何读取一个WAL log segment, - 流式复制: 通过TCP连接接收WAL log
- 异步(默认)
- 同步
- 日志归档: 每次会传输一个WAL log segment(16MB, 编译期决定), 在recovery.conf的
-
standby的类型:
standby可以是warm standby,仅用于与primary保持一致,作为备库使用;也可以是hot standby,在与primary保持一致的基础上对外提供读的功能。
需要注意的是,log shipping是异步的过程,也即当primary宕机的时候正在记录的WAL可能还没有同步到standby上,因此会造成standby上的数据丢失。这个数据丢失的时间窗口对于不同WAL传输方式可以做调整:
- 对于日志归档:可以调节
archive_time来缩短做WAL archive的周期(但是这会增加IO带宽的消耗) - 对于流式复制:其窗口会小的多
2.1 前提条件
对于运行primary机器和standby机器,这种高可用方案有以下的条件:
- 系统架构应该保持一致(32-bit or 64-bit)
- (如果使用了表空间)表空间相关的路径应该保持一致
- PG版本相同
2.2 standby的行为
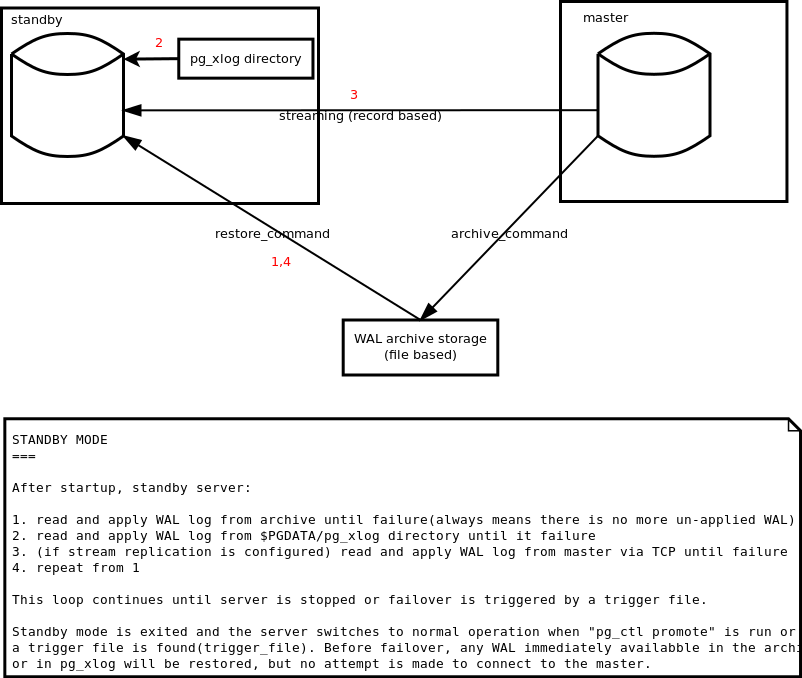
如上图所示,一个DB实例有一个模式叫做Standby Mode/Recovery Mode(细分为catchup mode + streaming mode),在这个模式下它会不断地去读WAL,然后应用到自身。
而退出这个模式的条件有三个:
- DB被停止 -> stop mode
pg_ctl promote在standby上被执行 -> ?- trigger file在standby上被创建 -> ?
2.3 配置primary
2.3.1 基于文件的log-shipping
配置continuous archiving,归档的目标地址应该是一个standby也能访问的路径(即使primary宕机).
2.3.2 基于流的log-shipping
- 创建一个供standby用来复制的role
-
pg_hba.conf
- 为standby的这个role创建db为
replication的访问项
- 为standby的这个role创建db为
-
postgresql.conf:
- 设置
wal_level为至少replica - 设置
max_wal_senders为适当值 - 设置
listen_address - 设置
max_replication_slots为适当值 - 设置
full_page_writes为on(默认即为on),这是运行pg_basebackup的前提条件 - 设置
wal_log_hints为on(默认为off);或者,在初始化的时候(initdb)加入--data-checksums选项。这是运行pg_rewind的前提条件 - 设置
wal_keep_segments为一个非零值(默认为0),这用于standby的复制和pg_rewind比较WAL的过程(虽然standby的复制可以通过slot来保证WAL不会由于过期被删除)。 - (如果流是基于TPC的)设置
tcp_keepalives_idle,tcp_keepalives_internal,tcp_keepalives_count
- 设置
- 为standby创建一个复制槽
2.3.3 基于以上两者
都要设置。
2.4 配置standby
-
先在standby机器上从basebackup恢复
可以使用
pg_basebackup的如下命令:# rm -rf $PGDATA # pg_basebackup -D $PGDATA -F p -R -S [slotname] -X stream [-c fast] -d [connstr]其中
connstr的说明可以参见官网,一个简单的例子如下:postgresql://user:password@host:port[/dbname]?application_name=foobarconnstr相对于在命令行上以-h,-U等来指定连接参数的好处:- 它可以指定密码,否则的话你需要准备一个~/.pgpass文件来存放密码
- 它允许加入额外的连接参数(例如:
application_name),而这些额外的连接参数会被加入到创建出来的recovery.conf文件中
-
新建一个recovery.conf文件(如果使用pg_basebackup恢复的话,加入
-R参数可以自动创建该文件),在文件中做如下配置:- 设置
standby_mode为on - (如果使用基于文件的log-shipping) 设置
restore_command去拷贝WAL archive - (如果你要设置多个standby)设置
recovery_target_timeline为latest, to make the standby server follow the timeline change that occurs at failover to another standby. 例如,对于一个priamry+standby的高可用架构,如果创建一个standby指向高可用的VIP,那么这个新创建的standby需要设置recovery_target_timeline为latest,从而确保当高可用发生容灾之后(standby promote,timeline+1)依然可以用新timeline的wal日志 - (如果使用基于流的log-shipping)设置
primary_conninfo,其内容称为libpq connection string,包括host name(or IP)和其他额外的选项(例如:密码)示例:user=postgres host=170.17.0.1 port=32810 sslmode=prefer sslcompression=1 krbsrvname=postgres - (如果使用基于流的log-shipping)设置
primary_slot_name
- 设置
-
由于这个standby在容灾后会成为primary,因此需要像之前的primary一样做基于文件或者基于流的log-shipping的配置。不过这些配在做basebackup的时候都已经被同步到standby了,所以没有额外的需要做的。当容灾后,记得在新的pirmary上重新创建replication slot.
2.5 流式复制(streaming replication)
流式复制默认是异步的.
如果仅使用流式复制而没有配置日志归档(file based continuous archive),则primary可能在standby接收到某些WAL之前将其回收。如果要避免这种情况,可以为standby配置复制槽(replication slot). 当然,如果配置了日志归档,也可以避免这种情况,因为这些被回收的日志一定会先被归档,从而使得standby可以读取并应用。
流式复制在primary和standby的基本配置在上面两节已经提过。
在standby与primary的连接被成功建立起来之后,你会在standby系统中看到多了一个walreceiver进程;在primary系统中看到多了一个walsender进程。
2.5.1 权限
由于WAL中包含敏感信息,因此primary应该仅允许信任的standby接收这些WAL流。而这些standby连接primary的帐号也需要有superuser权限,或者至少有REPLICATION权限,建议创建一个特殊的账户,仅拥有REPLICATION和LOGIN权限,用于复制,这样可以避免standby修改primary的数据。因此,正确的步骤如下:
-
在primary上为standby创建一个复制帐号
foo,设置密码,并且给予其REPLICATION和LOGIN的权限:postgres=> CREATE USER foo WITH LOGIN REPLICATION PASSWORD '123'; -
在primary上为
foo开通访问权限(假设standby的IP是192.168.1.100):修改pg_hba.conf:
# Allow the user "foo" from host 192.168.1.100 to connect to the primary # as a replication standby if the user's password is correctly supplied. # # TYPE DATABASE USER ADDRESS METHOD host replication foo 192.168.1.100/32 md5 -
在standby上设置连接primary的连接字符串(connection string):
修改recovery.conf(假设primary的IP是192.168.1.50):
# The standby connects to the primary that is running on host 192.168.1.50 # and port 5432 as the user "foo" whose password is "123". primary_conninfo = 'host=192.168.1.50 port=5432 user=foo password=123'注意,这里的密码也可以放在 ~/.pgpass 文件中。
2.5.2 监控
使用流式复制的时候,需要关注有多少WAL是primary中产生的,但是还没有应用到standby。这两个信息可以分别通过以下操作获得:
- 在primary上执行
pg_current_xlog_location - 在standby上执行
pg_last_xlog_receive_location
想要知道详细的信息,可以通过在primary上执行pg_stat_replication来获得详细的统计项进一步分析,例如:其中有一项叫做sent_location(表示上一个通过TCP连接发送出去的WAL的位置),如果sent_location和pg_current_xlog_location差距很大,则说明primary现在负载很高;如果sent_location和pg_last_xlog_receive_location相差很大,则说明有网络延迟或者standby负载很高。
2.6 复制槽(replication slots)
复制槽提供以下几个作用:
- 避免primary将还未应用到standby的WAL删除
- 即使standby当前没有连接到primary,primary也不会把可能导致恢复冲突(recovery conflict)的行删除。
2.6.1 查看和操作复制槽
每一个复制槽都有一个名字,其状态可以通过pg_replication_slots视图来查看,同时也可以通过流复制协议或者SQL函数来创建或删除。
2.6.2 简单例子
在primary上建立一个复制槽:
postgres=# SELECT * FROM pg_create_physical_replication_slot('node_a_slot');
slot_name | xlog_position
-------------+---------------
node_a_slot |
postgres=# SELECT * FROM pg_replication_slots;
slot_name | slot_type | datoid | database | active | xmin | restart_lsn | confirmed_flush_lsn
-------------+-----------+--------+----------+--------+------+-------------+---------------------
node_a_slot | physical | | | f | | |
(1 row)
在standby上使用这个复制槽:
standby_mode = 'on'
primary_conninfo = 'host=192.168.1.50 port=5432 user=foo password=foopass'
primary_slot_name = 'node_a_slot'
2.7 级联复制
既作为sender又作为receiver的standby称为cascading standby:
upstream server -> cascading standby -> downstream server
目前的cascading standby都是异步的,所有同步的设置(在下一节讲到)在级联模式下不起作用。
2.8 同步流式复制
异步流式复制引入一个时间窗口,当primary宕机之后,刚产生的事务可能还没有复制给standby,导致两边状态不一致。
同步复制提供了一种手段去保证当前复制的事务被一个或多个standby所应用。这种等级的保护称为2-safe replication, 如果synchronous_commit被设为remote_write,则等级变为group-1-safe.
同步复制的缺陷在于,它增加了响应时间,大于等于primary到standby的round trip时间。
Read only transactions and transaction rollbacks need not wait for replies from standby servers. Subtransaction commits do not wait for responses from standby servers, only top-level commits. Long running actions such as data loading or index building do not wait until the very final commit message. All two-phase commit actions require commit waits, including both prepare and commit.
2.8.1 基本配置
2.8.1.2 配置primary
- 按照上面流式复制配置的那一章做配置
- 在postgresql.conf中设置
synchronous_commit为on(on是默认)。值得注意的是,synchronous_commit可以在不同的级别被打开或者关闭,包括用户级别,DB级别,transaction级别。 -
在postgresql.conf中设置
synchronous_standby_names,格式为:num_sync ( standby_name[, ...] ) or standby_name [, ...]The synchronous standbys will be those whose names appear earlier in this list, and that are both currently connected and streaming data in real-time (as shown by a state of streaming in the pg_stat_replication view). Other standby servers appearing later in this list represent potential synchronous standbys. If any of the current synchronous standbys disconnects for whatever reason, it will be replaced immediately with the next-highest-priority standby. Specifying more than one standby name can allow very high availability.
第一种形式中,
num_sync是primary需要等待的reply的从库的数目。例如:3(s1,s2,s3,s4)代表这次事务需要等待s1-s4中的任意三个.第二种形式等价与第一种形式中的
num_sync等于1.如果这个设置为空,那么同步机制不会生效。
另外值得注意的是,这个参数是可以运行时被动态修改的。
2.8.1.2 配置standby
- 按照上面流式复制配置的那一章做配置
- 如果postgresql.conf中的
wal_receiver_status_interval为非0(默认为10 sec),那么每次commit,都可以立即在primary的pg_stat_replication视图中看到复制进度的更新 - 在recovery.conf的
primary_conninfo中加入application_name这个设置,这个会被用于primary中的synchronous_standby_names的设置。
2.8.3 性能
同步复制会降低系统性能,考虑一种情况:应用的10%的I/O是需要保证数据一致性,而90%的I/O是无关紧要的。这种情况下如果盲目地全局使用同步复制是不明智的。
由于PG支持事务级别的同步,因此针对上面的场景,建议的做法是在应用程序中做同步/异步复制的控制,即在事务中执行SET LOCAL synchronous_commit TO on/off/remote_write/....
2.8.3 高可用
高可用的最好的解决方案是同步复制+多个从库(总是保证有potential standby),这样可以保证主库不会由于一个同步从库的宕机而被阻塞。
不过,另外一种可能的方案是同步复制+一个从库,然后使用一个第三方哨兵节点来检测从库状态。当发现从库服务不正常的时候,在primary上面动态修改postgresql.conf中的synchronous_standby_names为空,然后执行pg_ctl reload,即退化为异步复制(这个操作会使被hang住的客户端程序恢复);后续当这个从库恢复服务之后并被哨兵节点感应到,哨兵节点再动态地设置为同步。
standby在启动后首先会进入catchup mode,则这个模式下standby会追primary的WAL。直到第一次完全追上primary的WAL之后,standby会进入streaming state。如果standby停止服务,那么它又进入catchup mode。仅当standby处于streaming mode的情况下,它才是一个同步standby,也即primary会在每一个WAL复制时等待standby的响应。
如果主库在等待ACK的过程中重启了,那么主库会认为上一次的transaction是成功的。然而,同步复制此时可以保证的是,客户端程序不会收到成功的返回。因此,当这种情况发生之后有两种处理方式:
-
维持重启的DB为主库,那么所有同步的从库都会进入catchup mode,然后将刚才那条事务接收到。而客户端程序需要确认上一次的操作是否已经成功(因为前一次很可能因为DB挂掉而超时或者返回失败),如果判断已经成功,那么同样的事务不需要再做第二次。也就是说,客户端程序对这种敏感的操作总是要在写操作之后读一下来验证(如果单纯依赖于返回值,可能会导致双重操作的问题,例如对于金融应用,可能引起double payment);
-
重启的DB被downgrade为从库,而之前的某个从库被提升为主库,那么这个新的主库之前可能接收到了这个事务,也可能没有。此时,应用程序依然需要确认上次操作结果。
2.9 从库持续归档
When continuous WAL archiving is used in a standby, there are two different scenarios: the WAL archive can be shared between the primary and the standby, or the standby can have its own WAL archive. When the standby has its own WAL archive, set archive_mode to always, and the standby will call the archive command for every WAL segment it receives, whether it’s by restoring from the archive or by streaming replication. The shared archive can be handled similarly, but the archive_command must test if the file being archived exists already, and if the existing file has identical contents. This requires more care in the archive_command, as it must be careful to not overwrite an existing file with different contents, but return success if the exactly same file is archived twice. And all that must be done free of race conditions, if two servers attempt to archive the same file at the same time.
If archive_mode is set to on, the archiver is not enabled during recovery or standby mode. If the standby server is promoted, it will start archiving after the promotion, but will not archive any WAL it did not generate itself. To get a complete series of WAL files in the archive, you must ensure that all WAL is archived, before it reaches the standby. This is inherently true with file-based log shipping, as the standby can only restore files that are found in the archive, but not if streaming replication is enabled. When a server is not in recovery mode, there is no difference between on and always modes.
2.10 Failover
failover指当前的primary由于某种原因(宕机/网络拥堵/系统阻塞等)而被认为无法提供服务,将standby提升为primary的继续为外部提供服务的过程。
failover一般有以下几个过程:
- 保证standby处于streaming mode(而不是catchup mode)才可以继续failover
- 通过某种机制保证primary在下次恢复之后会触发failback以防止脑裂
- 将运行中的standby通过创建trigger_file(由recovery.conf指定)或者使用
pg_ctl promote来使其退出streaming mode,进入正常模式,对外提供服务 - 在这个新的primary上创建replication slot(详情见本小节尾部的注意事项)
- 将对外提供服务的网络从primary解绑,绑定到standby上
值得注意的是:
-
主从复制会复制数据和用户,但是不会复制创建的replication slot。一个直观的想法是在配置主从的时候在两个cluster都创建replication slot,但是问题是我们无法在启动standby以后在standby上执行任何sql命令。
所以,我们需要在每次failover的时候在新的primary上创建replication slot
-
如上所述,我们会在promote以后向pg发送命令,那么我们需要一种机制确保promote已经确实完成了。然而,实际上promote做的事情只是往
PGDATA目录中创建一个文件,告诉PG可以退出recovery mode。但实际上,PG还会做一些别的事情(例如:创建新的timeline)。所以,pg_ctl promote的结束不代表整个过程结束。在PG-v10版本以后,pg_ctl promote加入了-w选项,保证了这一点(详见)。而在那之前,我们需要自己去判断这一点(PG10以后的pg_ctl中是通过检查pg_controldata输出中的Database cluster state是否为in production来判断;另外,也可以通过pg_is_ready的返回,它内部是真正地尝试连接) -
pg_ctl promote并不会在提升过程中做check point,而是在promote以后,服务运行过程中自动做check point的。这在容灾的过程(尤其是手动切换)中会引起问题,pg_rewind(见下一节)会先获得timeline历史的分叉点。如果在做pg_rewind之前,新的primary(被promote的DB)还没有做check point,那么pg_rewind得到的历史分叉点是个错误的点。因此,我们应该在promote的过程中保证check point。在源码 pg_ctl.c(REL9_6_9) 中有这么一段注释:
For 9.3 onwards, “fast” promotion is performed. Promotion with a full checkpoint is still possible by writing a file called fallback_promote” instead of “promote”
而
pg_ctl promote实际做的事情也非常简单,它仅仅是在$PGDATA下面创建了一个名为promote的文件,然后kill -SIGUSR1postmaster。因此,我们在做promote的时候可以不选择pg_ctl promote,而是自己创建一个fallback_promote文件,然后手动kill服务。
2.11 Failback
failback指primary在恢复服务之后将自己降级为standby的过程。
failback一般有以下几个过程:
- 停止target cluster
- 在target cluster上执行
pg_rewind - 在target cluster上创建recovery.conf
- 启动target cluster
pg_rewind的工作原理如下:
- 比对target cluster(即,待rewind的cluster)和 source cluster,找到timeline历史分叉点 。寻找的过程大致为:在target 和 source 分别通过它们的 global/pg_control ,以及 pg_xlog/.history* 获得当前的timeline history,然后进行比对,找到第一个分叉点
- 扫描target cluster的WAL,从source cluster的timeline历史分叉的点之前的第一个checkpoint开始。对于这段区间内每一个WAL,会记录相应的data block
- 将上面记录的data block从source cluster拷贝过来,可以从运行时的source cluster拷贝(
--source-server),也可以从停止了的source cluster拷贝(--source-pgdata) - 将其余的文件(除了relation文件外,例如
pg_clog/配置文件等)从source cluster拷贝过来 - 在target cluster的data目录下创建一个backup_label文件,指向搜索开始的checkpoint,用于当target cluster启动后应用WAL日志
其中有以下几点需要注意:
- 如果使用
--source-server从运行时的source cluster拷贝,则连接参数中的db用户一定要有SUPER权限 - 由于要拷贝relation文件外的其他文件,因此要保证这些文件在target cluster上都有访问权限
- 执行
pg_rewind的时候,target cluster是停止状态 - source/target cluster postgresql.conf中设置
wal_log_hints为on(默认为off);或者,在初始化的时候(initdb)加入--data-checksums选项。这是运行pg_rewind的前提条件 - source/target cluster postgresql.conf中设置
wal_keep_segments为一个非零值(默认为0),这是为了防止当在target cluster上执行pg_rewind后它去source cluster比较WAL的时候source cluster中已经将某些WAL删除了 pg_rewind结束后,如果直接启动target cluster,它会进入primary mode。如果想要让target cluster继续follow source cluster,我们需要在target cluster的PGDATA目录下添加一个recovery.conf文件
2.12 实践
2.13 高可用PITR的几个tips
2.13.1 高可用恢复过程
-
创建一个新的高可用实例,然后做PITR恢复:
这么做的好处在于,原有高可用实例可以维持服务。在验证恢复成功后,再将开放连接。
-
PITR恢复已有的高可用实例
恢复的步骤也有两种:
- 先恢复primary,然后将standby重做(即对新的primary做basebackup,然后配置recovery.conf,启动)。这种做法会需要两次basebackup拷贝的时间。
-
同时恢复primary和standby。之后,在从库上配置recovery.conf。这时候注意,如果你直接重启standby的话由于stop的时候会做一次checkpoint,导致从库的LSN比当前主库的LSN更新,那么从库会去向主库请求更新的LSN而失败。暂时我的做法是在主库上也做一次重启。
这种好处是basebackup的拷贝只需要一次。
值得注意的是,对于归档至实例所在的存储的情况(见2.13.2),在恢复前需要先stop主库,再stop从库。由于standby在关闭的时候不会主动switch WAL(事实上任何时刻都不会switch,standby的WAL的变化只会跟随主库),如果并行关闭primary和standby,那么此时可能导致两边archive目录的内容不一致,主库最后的switch WAL的事件并没有同步到从库,那么从库最后的那个WAL依然是当前active的WAL,并且没有被archive。如果接下来要归档的时间刚好落在这个WAL里面,从库是没法恢复到正确的位置的。可能有的人会认为再次建立主从关系以后,从库会向主库请求新的
2.13.2 高可用归档策略
-
归档至独立存储
这个比较简单和直接,设置
archive_mode = on,这样就只有primary会在每次switch wal的时候归档,standby只接收wal,而不会归档。 -
归档至实例所在的存储
-
为了保证主从都有archive,需要将
archive_mode = always,这样从库接收到主库的wal之后也会archive -
(如果archive存在PGDATA目录下) PITR恢复主库的时候需要忽略archive目录,例如通过
rsync将主库的PGDATA与basebackup目录进行同步的时候,应该–exclude archive目录,否则archive目录会被同步为basebackup时候的状态 -
为了保证主从的archive都是完整的,在PITR恢复完主库之后,创建从库的时候使用的
pg_basebackup命令应该不传输wal,也即:不添加-X参数(10.4以后,可以设置-X none)。否则,pg_basebackup会将basebackup过程中产生的wal(至少一个,可能更多)直接拷贝至target目录(也即从库的PGDATA/pg_xlog),在从库起来以后对于pg_xlog下已经存在的wal,它不会再进行archive,也就是说这些wal在从库的archive目录下就丢失了
-
2.13.3 failover 和 PITR
以下仅适用pg-9.5+
假设有A和B两个单点DB,组成了一个高可用架构,A为初始的主库,B为初始的从库。
假设当前的WAL名为WAL1-1,然后发生了容灾,当B promote为主库的时候,在B上的WAL1-1还不是完整的,但是B又需要将timeline加一,并且生成新的WAL(称之为WAL2-1),那么B会将这个不完整的WAL1-1重命名为WAL1-1.partial(内容是一样的),然后对其进行archive。同时,从WAL1-1.partial拷贝出一个新的文件WAL2-1,并会作为当前的WAL继续接收新的LSN。
假设,如果有两个事务C1和C2发生在WAL1-1期间,如果此时发生容灾,在promote的主库上面此时生成的WAL2-1也包含了这两个C1和C2的事务(如上所述)。假设这时候,想要恢复到“C1发生以后,C2发生以前”,那么需要指定的recovery_target_timeline应该是2,因为WAL1-1.partial虽然被archive了,但是不会被用于recovery。
这就引发一个问题,当用户指定一个时间点,如何确定这个时间点对应的tiemlineID?有以下几个思路:
- 在
archive_command中监控timeline切换的事件,如果发生了的话记录下当时的时间点。之后将需要恢复到的时间点与这些记录进行对比即可。记录到的位置一定是在PGDATA目录以外的一个地方; - 见2.13.5
具体的关于parital的特性可以参考这篇文章。
2.13.4 hot standby 和 PITR
官网上关于hot_standby的定义如下:
hot_standby(boolean) Specifies whether or not you can connect and run queries during recovery, as described in Section 25.5. The default value is off. This parameter can only be set at server start. It only has effect during archive recovery or in standby mode.
所以,对于warm standby,仅在recovery.conf中指定standby_mode = on,才会将自己作为一个从库;而对于hot standby,除了前者这种情况,还有一种情况会把自己作为从库是当在postgresql.conf中指定hot_standby = on,并且处于archive recovery,即在recovery.conf中指定了restore_command。
假设,高可用的配置中从库是hot standby(可能是为了容灾监控或别的什么原因),然后在从库上做了basebackup。那么,当主库使用这个basebackup做恢复的时候,由于postgresql.conf中的hot_standby = on,那么恢复之后的主库会是一个hot standby。需要在恢复之后对它再做一次promote才可以。或者,在恢复前把hot_standby设为off.
2.13.5 根据时间点获取它当时的timeline
如果需要对一个DB实例反复做PITR,或者对一个容灾过的DB做PITR,需要指定timelinID。实际上,当指定某个时间之后,用户就是想恢复到那个时间点的实际的状态。而某个时间点,PG一定是处于某一个timeline上的。所以,timeline和datetime的关系实际上应该是1-1对应的。但是,PG并没有帮我们做这个映射的记录,需要我们自己解决。
一种直接的想法是,可以在archive_command中对目标archive文件的文件名和当时的时间戳建立一个映射关系;要恢复的时候,根据传入的时间找到对应时间戳的archive文件名,同时也就确定了它的timeline,然后就可以根据timeline和传入的时间进行恢复。
还有一种比较hardcore的方法,是通过解析archive的文件,将指定的时间与每个文件中的Transaction中的COMMIT时间对比,找到第一个包含指定时间或者第一个最接近的并且比指定时间早的wal文件,取它对应的timeline作为相应的timeline. 实现可以参考这里.
注意这里所说的第一个比指定时间早的最少的!为什么单纯找一个最后一个比指定时间早的wal是不成立的?这就要谈谈WAL的内容了:假设现在有WAL1-1(active),里面包含了两个COMMIT:C1,C2。此时,发生PITR,恢复到”C1之后,C2之前”。那么,新生成的WAL2-1中会包含C1,假设WAL2-1在switch前没有任何事务,那么WAL2-1就是一个仅包含C1的文件。如果,现在我们此时又想恢复到”C2以后”,那么如果找最后一个比指定时间早的wal,满足条件的是WAL2-1,但是实际上WAL2-1并不包含C2,因此会得出错误的结果。事实上我们要找的其实是比指定时间早的最少的的wal,也就是WAL1-1(WAL1-1中C2相对于指定的”C2以后”比WAL2-1中的C1相对于其更接近)。
那么,为什么又要加一个第一个这个条件呢?按照刚才的例子,假设在恢复到”C1之后,C2之前”以后,我们再做一次同样的恢复(C1之后,C2之前),那么这时如果不指定第一个这个条件,我们找到的WAL是WAL2-1.这虽然不会影响恢复结果,但是毕竟还是不精确的,不能反映真实的情况(真实的情况是当时那个时间点我们处于timeline1),作为一个严谨的程序员,我们应该指定条件为第一个比指定时间早的最少的!!!
另外,需要注意的是,所有的恢复都是基于一个basebackup的,我们不应该比较所有archive的wal,而是应该从basebackup中指定的wal作为起点开始寻找。并且,上述的第一个比指定时间早的最少的wal这种定义导致我们只能线性地从小到大比较,而不能用二分查找法。
2.13.5 standby 向 primary 请求WAL的过程
见下面的时序图(来自The Internals of PostgreSQL):
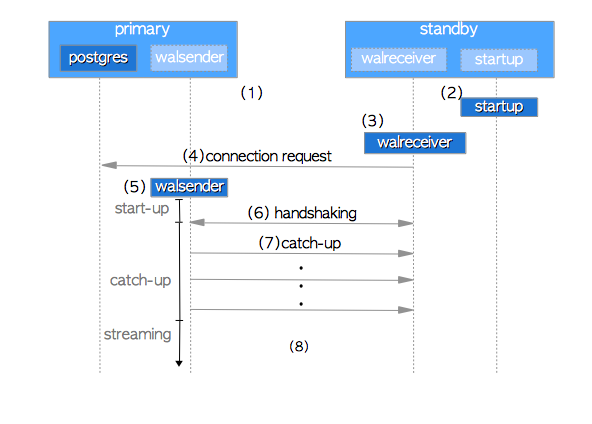
- Start primary and standby servers.
- The standby server starts a startup process.
- The standby server starts a walreceiver process.
- The walreceiver sends a connection request to the primary server. If the primary server is not running, the walreceiver sends these requests periodically.
- When the primary server receives a connection request, it starts a walsender process and a TCP connection is established between the walsender and walreceiver.
- The walreceiver sends the latest LSN of standby’s database cluster. In general, this phase is known as handshaking in the field of information technology.
- If the standby’s latest LSN is less than the primary’s latest LSN (Standby’s LSN < Primary’s LSN), the walsender sends WAL data from the former LSN to the latter LSN. Such WAL data are provided by WAL segments stored in the primary’s pg_xlog subdirectory (in version 10 or later, pg_wal subdirectory). Then, the standby server replays the received WAL data. In this phase, the standby catches up with the primary, so it is called catch-up.
- Streaming Replication begins to work.
我们这里重点要说的是第六点和第七点:
- 第六点告诉我们,从库是从当前最新的LSN开始向主库去索取的,这意味着如果从库之前的LSN与主库有不一致,那么创建出来的主从数据依然不一致
- 第七点告诉我们,如果主库有比从库当前LSN更新的LSN,那么主库会将从这个LSN开始到自己最新的LSN这个范围内的所有LSN都发送给从库。注意,这是一个闭区间,即从库发送给主库的这个LSN对应的主库上的LSN,主库也会发回给从库,从而覆盖从库中原本的那条LSN。
2.13.6 HA的从库
如果创建一个从库,以高可用集群中的某一个库或者高可用集群对外的VIP(如果有的话)为上游主库的话,这个从库需要在recovery.conf中设置recovery_target_timeline = 'latest'。这样,高可用集群即使发生容灾,timeline增加,这个从库也可以将这个改动应用到自身,然后继续follow这个高可用。
3. 服务器设置
3.1 WAL设置
下表列出几个重要的WAL相关的参数:
| 参数 | 类型 | 默认值 | 启动后可更改 | 描述 |
|---|---|---|---|---|
wal_level |
enum | minimal | no | - minimal: 记录的信息仅能从crash或者立即关机状态下恢复数据 - replica: 记录的信息可以用于WAL archive或者只读从库 - logical: 支持逻辑解码 |
fsync |
bool | on | no | 保证每一次更新动作都调用wal_sync_method中指定的方式写入磁盘注意:设置为off可能会导致数据库内部数据不一致 |
synchornous_commit |
enum | on | yes | 返回成功前是否等待WAL写入磁盘(如果synchronouns_standby_names非空,也会影响从库)- off: 不会导致数据库内部数据不一致,但是可能导致客户端/从库与服务器端状态不同步 - on: 等待服务器以及其从库收到commit并且写入磁盘才返回 - remote_apply: 等待服务器以及其从库收到commit并且应用才返回(此时读操作可以看到变化) - remote_write: 等待服务器以及其从库收到commit并且写入操作系统(写队列)才返回,但是并不保证写入到磁盘(这可以保证DB实例crash不会导致数据丢失;但是操作系统的crash会导致数据丢失)。不过只要主库还在,下一次从库起来以后可以继续追上。唯一可能丢失数据的情况是,主库和从库同时挂掉,并且主库的数据库无法恢复。因此,这个选项相对安全,并且比 on更高效。- local: 仅等待服务器收到commit并且写入磁盘才返回 |
wal_writer_delay |
integer | 200ms | no | 等多久之后将WAL写入到磁盘,在这个时间点之间的WAL仅写入操作系统的写队列,并没有写入磁盘 |
wal_writer_flush_after |
integer | 1MB | no | 写了多少WAL之后将WAL写入到磁盘,在这个时间点之间的WAL仅写入操作系统的写队列,并没有写入磁盘 |
98. 零散的知识
98.1 docker exec 执行 pg_ctl 会卡住
这是因为docker exec执行每一条命令,在非detach的情况下不但会等待命令返回,还会等待当前执行的命令的标准输出完成。具体可以参加docker cli的源码,如下:
文件:cli/cli/command/container/exec.go:
// 注意:即使没有加-i也会进入这个函数,-i只是判断是否在attach模式下attach stdin(默认只attach stderr,stdout)
func interactiveExec(ctx context.Context, dockerCli command.Cli, execConfig *types.ExecConfig, execID string) error {
...
errCh := make(chan error, 1)
go func() {
defer close(errCh)
errCh <- func() error {
streamer := hijackedIOStreamer{
streams: dockerCli,
inputStream: in,
outputStream: out,
errorStream: stderr,
resp: resp,
tty: execConfig.Tty,
detachKeys: execConfig.DetachKeys,
}
return streamer.stream(ctx)
}()
}()
...
if err := <-errCh; err != nil {
logrus.Debugf("Error hijack: %s", err)
return err
}
...
}
文件:cli/cli/command/container/hijack.go
// stream handles setting up the IO and then begins streaming stdin/stdout
// to/from the hijacked connection, blocking until it is either done reading
// output, the user inputs the detach key sequence when in TTY mode, or when
// the given context is cancelled.
func (h *hijackedIOStreamer) stream(ctx context.Context) error {
...
}由上面那段stream()的注释可以知道,这个函数返回的条件有以下几个:
- 待执行命令输出结束
- 用户在TTY模式下输入detach key sequence
- 函数中的context参数被取消/超时
其中,我们可以排除2和3(因为context在exec.go中是context.Background)。而pg_ctl如果不加-l,则会一直往标准输出打log:
man pg_ctl: On Unix-like systems, by default, the server’s standard output and standard error are sent to pg_ctl’s standard output (not standard error). The standard output of pg_ctl should then be redirected to a file or piped to another process such as a log rotating program like rotatelogs; otherwise postgres will write its output to the controlling terminal (from the background) and will not leave the shell’s process group.
从而导致docker exec一直卡住。
解决的办法就是给pg_ctl加上-l参数。
99. 中间件
99.1 pgPool2
- session级别的连接池
- 复制,自动failover/failback
- 负载均衡
- 达到最大连接时,新连接被加入等候队列(而不是默认的返回错误)
99.2 pgbouncer
支持不同级别的连接池,包括:
- session pooling
- transaction pooling
- statement pooling
99.3 HAProxy
通用的负载均衡组件,支持TCP/HTTP代理。同时,与keepalived高度集成,支持高可用。
99.4 Repmgr
对官方提供的复制功能的增强,支持自动failover/switchover。
Comments