《Fluent Python》读书笔记
下文所有的内容都是针对Python3而言…
Prologue
1. The Python Data Model
第一章,作者粗略地介绍了Python中的数据模型,主要是为了展示Python是如何将各种 magic method 和特定语法结合起来,从而使开发人员自定义的类可以大量使用Python中已有的内置函数。
1.1 dunder method
Python中有很多 magic method,被 __ 所包围(例如 __getitem__)。这些特殊的方法会在各种不同的场景下被调用(例如 l[0]调用了l.__getitem___(0))。这类方法有个 pythonic 的名字,称为: dunder method.
一般对于 dunder method 是不会直接调用的(除了: __init__),并且程序员应该避免将自己使用的函数写成 dunder method 的形似,一来可以避免和以后的magic method冲突,而来防止和未来标准中新定义的magic method冲突。
1.2 __repr__ vs __str__
__repr__ 应该返回对象的代码表示,用于给解释器看;__str__应该返回对象的信息,用于给人看。
当__str__没有实现的情况下,Python 会 fallback使用__repr__.
1.3 bool()
在 if, while, 或者一些逻辑表达式中,表达式本身会被调用bool(),返回 True 或者 False.
默认情况下,对于一个用户自定义的类型,Python按下面的顺序去评估bool()的返回值:
- 如果没有实现
__bool__或者__len__,返回True; - 否则,如果实现了
__bool__,则返回__bool__的返回值(TrueorFalse); - 否则,如果实现了
__len__,则如果返回非0,则为True,否则为False.
Data Structures
2. An Array of Sequences
如果按照存储的是对象实体还是对象的引用来区分sequence,那么可以分为以下两类:
Container Sequences
list, tuple, collections.deque
Flat Sequences
str, bytes, bytearray, memoryview, array.array
Container Sequence可以保存任意不同类型对象的引用,而Flat Sequence只能保存特定某种类型的对象的实体。
如果按照是否mutable来区分sequence, 可以分为以下两类:
Mutable Sequences
list, bytearray, array.array, collections.deque, memoryview
Imuutable Sequence
str, bytes, tuple
下图展示了ABCmodule所提供的两个sequence基类的UML图,可以给人一个直观的感受 mutable sequence 和 immutable sequence 在内部实现上的差距:
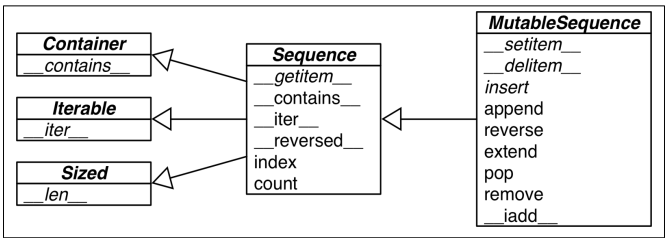
(注意:built-in的sequence并没有继承ABC module中的类)
2.1 listcomp & genexp
Python3中的listcomp不再leak内部变量了:
In [1]: x = 'ABC'
In [2]: dummy = [ord(x) for x in x]
In [3]: dummy
Out[3]: [65, 66, 67]
In [4]: x
Out[4]: 'ABC'
使用listcomp构造list/tuple/map/…的好处有:
- 可读性强,让人一目了然的知道是在构造一个list/tuple/map/…
- 有时候更快
genexp相对于listcomp来说,可以节省内存。因为它并不是一次性构造出目标sequence,而是创建一个iterator,每次迭代只返回下一个元素。
2.2 Tuple
tuple有两个作用:
- 用于一串record,类似C++中的POD类。每一个域的值是不变的,并且域和域之间是固定的顺序
- 作为imuutable的list
2.2.1 Tuple Unpacking
tuple还支持 tuple unpacking 的操作,允许将任意iterable中的元素unpack到等号左边的tuple中去,例如:
In [1]: a,b = (1,2)
In [2]: a
Out[2]: 1
In [3]: b
Out[3]: 2
In [4]: a, b = b, a
In [5]: a
Out[5]: 2
In [6]: b
Out[6]: 1
In [7]: a, b, *l = (1,2,3,4,5)
In [8]: l
Out[8]: [3, 4, 5]
In [10]: a, *l, b = (1,2,3,4,5)
In [11]: l
Out[11]: [2, 3, 4]
In [12]: a, (b1,b2), c = (1,(2,3), 4)
In [13]: b1
Out[13]: 2
另外,在函数调用的时候,也可以使用 unpacking/packing. 调用者使用的时候是 unpacking 的过程;函数定义中使用的时候是packing 的过程。
2.2.2 Named Tuples
collections.namedtuple 提供了有名tuple. 这种tuple和内置的tuple的内存消耗量是一样的(因为名字是存在类里,而不是实例当中)。
Named tuple很适合用于record。
2.3 Slicing
slice是一个很常见的操作,例如:
In [28]: s = "bicycle"
In [29]: s[::3]
Out[29]: 'bye'
a:b:c 只在[]中有效。在内部实现中,a:b:c会被转化成一个 slice object: slice(a,b,c). 这个 slice object 会作为输入参数传给 __getitem__(). 因此:
s[::3] ---> s.__getitem__(slice(0, len(s), 3))
在某些多维数组的实现中(例如numpy.ndarray),[]也接受以逗号分隔的多个index或者slide, 这等价于将多个 slice object 组成的tuple作为参数传给 __getitem__():
In [22]: array = numpy.zeros((2,5))
In [23]: i = 0
In [24]: for x in range(array.shape[0]):
...: for y in range(array.shape[1]):
...: array[x,y] = i
...: i += 1
...:
In [25]: array
Out[25]:
array([[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.]])
In [27]: row = slice(0,2)
In [28]: col = slice(0,3)
In [30]: array.__getitem__((row, col))
Out[30]:
array([[ 0., 1., 2.],
[ 5., 6., 7.]])
In [31]: array[row, col]
Out[31]:
array([[ 0., 1., 2.],
[ 5., 6., 7.]])
...在python中是作为Ellipsis(ellipsis类的singleton实例)的别名,可以被作为参数传给函数,例如:
f(a, ..., z)
a[i:...]
目前为止,标准库中还没有使用...的函数,但是在numpy中大量存在。
Comments